Titanic Survival Prediction: Battle of Algorithms (KNN vs Decision Tree)
Welcome back to the lab. 🧪
Today, I am putting two classic Machine Learning algorithms into the ring to fight it out: K-Nearest Neighbors (KNN) vs. Decision Tree.
My goal with this experiment wasn’t just to get a high accuracy score on the famous Titanic Kaggle dataset. It was to get my hands dirty with Scikit-Learn, understand data preprocessing basics with Pandas, and see firsthand how different models require different treatment (especially scaling).
Here is my log of the experiment.
1. Setting Up the Workbench
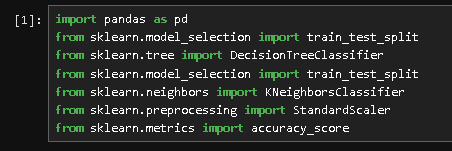
First, I needed to import the necessary tools. I used pandas for handling the data and various modules from sklearn for the models and metrics.
2. Preparing the Data
Data never comes clean. For this experiment, I focused on the ‘train’ dataset. I dropped the PassengerId (irrelevant to survival) and separated the target variable (Survived) from the features.
Then, I used train_test_split. This is crucial because we need to hide some data from the model to test it fairly later. I set aside 30% of the data for testing.

3. The Critical Lesson: To Scale or Not to Scale?
This was the most important realization of the project.
KNN (K-Nearest Neighbors) works by calculating the mathematical distance between points. If one feature is “Age” (0-80) and another is “Fare” (0-500), the “Fare” will dominate the distance calculation just because the numbers are bigger.
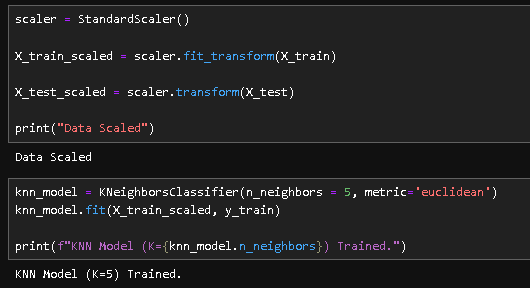
To fix this, I used StandardScaler to normalize the data for KNN.
However, Decision Trees don’t care about distance; they just ask “Is X greater than 5?”. So, scaling isn’t strictly necessary for them, but it is vital for KNN.
4. Training the Decision Tree
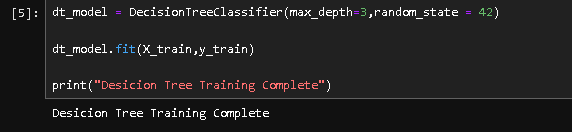
Next, I trained the Decision Tree. I limited the max_depth to 3. Why? Because if a tree gets too deep, it memorizes the data (overfitting) instead of learning the patterns. I wanted a simple, generalizeable model.
5. The Results: Who Won?
After training both models, I made them predict the survival of the passengers in the test set (the 30% we hid earlier).
I calculated the accuracy score for both.
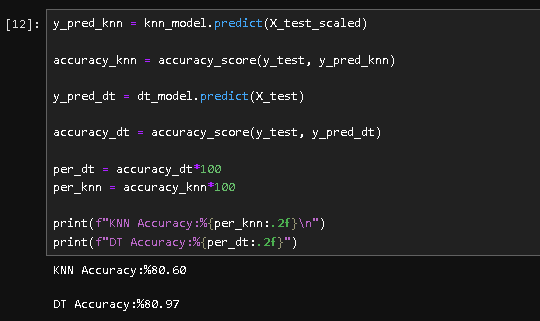
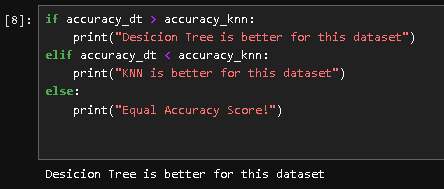
Finally, I wrote a simple logic to compare them and announce the winner automatically.
Conclusion
In this specific run, the Decision Tree (80.97%) slightly outperformed KNN (80.60%).
Even though the difference is small (< 1%), the process taught me a lot:
- Preprocessing varies: KNN needs scaling, Trees generally don’t.
- Scikit-learn is consistent: The
.fit()and.predict()logic is the same for almost every model, which makes switching algorithms very easy.
Next time, I plan to dive deeper into “Hyperparameter Tuning” to see if I can push these scores even higher!



